사용자 수에 따른 아키텍처 구성
1. 사용자가 본인 1명일 때
가장 먼저 EC2 생성
EC2위에 웹서버나 DB, 애플리케이션 등 설치해서 사용
고정 Public IP가 필요하기 때문에 Elastic IP 필요
Elastic IP는 DNS서비스인 Route 53으로부터 DNS 등록이 되고, 사람들은 이 DNS name을 통해서 우리가 만든 웹 애플리케이션에 접속하게 됨
관리는 쉽지만 모든 리소스가 하나의 인스턴스에 있기 때문에 장애 발생시 서비스가 바로 영향을 받게 된다

2. 사용자가 n명일 때 - 인스턴스 경량화
아무리 스케일링을 해도 나 혼자만 쓸 때보다는 결국에는 한계 용량에 도달하게 됨

먼저 기능에 따라 인스턴스의 역할을 나눈다
이 경우 DB 인스턴스를 분리시키면서 직접 관리할 것인지, 관리형 서비스를 이용할 것인지에 따라 어떤 AWS 서비스를 사용하게 될지, 본인이 직접 DB서버를 구축해서 사용할 것인지 등이 정해진다.
3. 베타 유저들이 유입되면서 100명단위로 늘어났을 때 - 관리형 서비스 고려
이제 DB에 점차 사용자들의 정보가 쌓이기 시작하면서 DB OS에 대한 패치나, DB에 대한 백업과 같은 작업에서 AWS 사용자가 직접 운영하는 데 부담이 생긴다. RDS가 바로 여기서 관리 부담을 덜어주기 위한 서비스인 것. AWS 사용자는 코어 서비스 개발에만 집중할 수 있게 된다.

4. 유저가 1000명까지 늘어난 경우 - 이중화
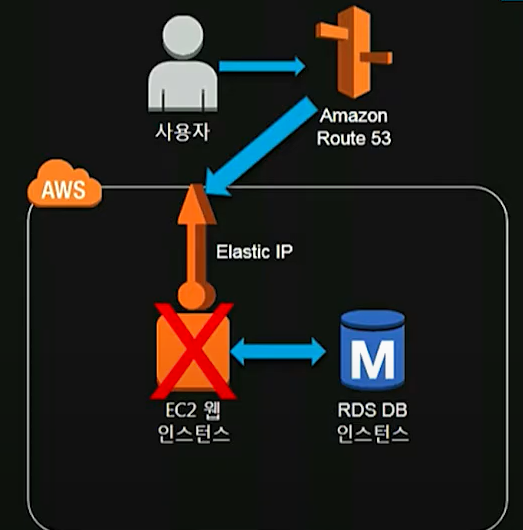
도표와 같이 이중화가 되어있지 않기 때문에 서비스 지속에 문제가 있다. 그래서 이중화가 권장된다.

여기서는 ELB의 도입이 권장됨. 기존 데이터센터에서 L4 스위치와 역할이 비슷하다.
웹서버용 인스턴스를 생성하고 ELB를 생성해서 부하를 분산하도록 구성한다.
RDS 의 Multi-AZ 옵션을 사용하면 각각의 가용영역에 Master와 Standby관계가 맺어지며 복제본이 생기고, 이 두 db는 동기화된다.
5. 사용자 10000명 이상 - 부하를 줄이기 위한 아키텍처 구성
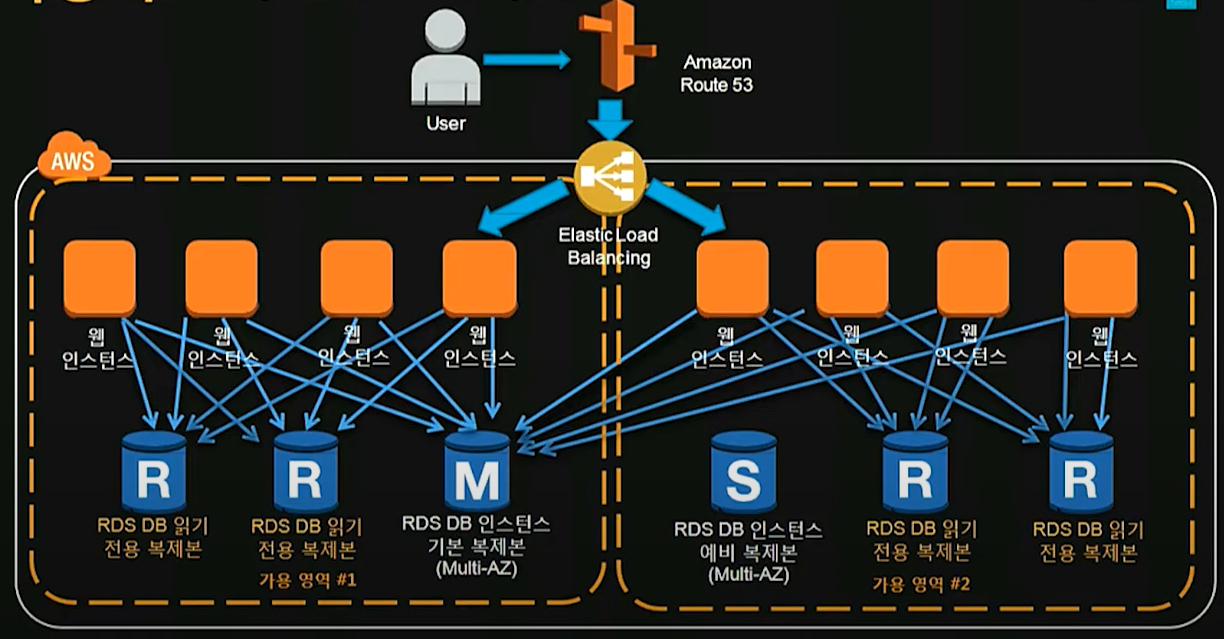
Multi AZ로 구성
각각의 가용 영역에 인스턴스 수 늘림
이 인스턴스는 하나의 마스터db에 읽기/쓰기를 하는데
쓰기 작업이 많아질수록 마스터db에 부하가 심해짐
이 때 읽기 전용 복제본(read replica)를 생성해서 각각의 가용영역에 복수의 읽기 전용 복제본을 생성하고 읽기 요청이 발생하면 그 read replica의 엔드포인트로 처리하도록 한다.
정적 콘텐츠를 S3와 CloudFront로 이전하기
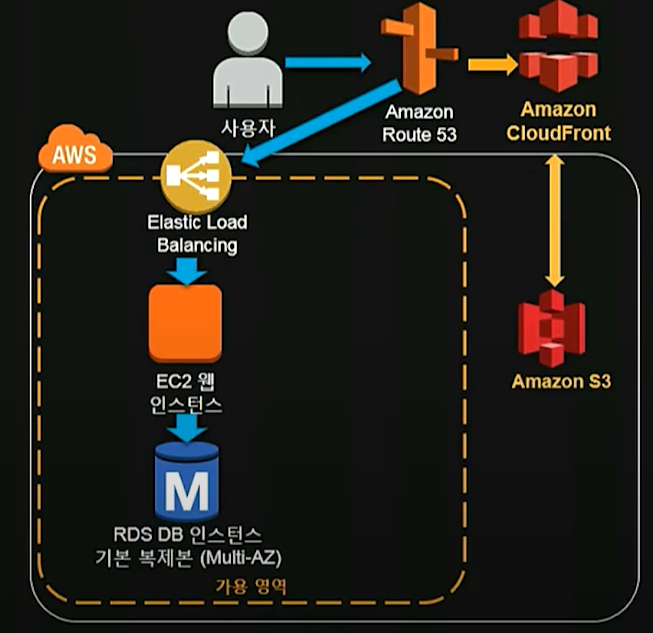
EC2 인스턴스 안에 html, css, js 파일 등을 넣어둔다면 유저가 컨텐츠를 요청할 때 웹서버에 지속적으로 부하를 일으킨다. 하여 이런 컨텐츠는 모두 S3에 넣어두고 자주 사용하는 컨텐츠는 CloudFront로 캐시함으로써 가장 가까운 엣지로케이션에서 라우팅을 받는다. 단순히 구성만 바꿨을 뿐인데 유저는 빠르게 컨텐츠를 제공받을 수 있고, 웹서버는 부하를 줄일 수 있는 효과를 보게 된다. 그래서 솔루션 아키텍팅이 중요한 것.
ElasticCache 또는 DynamoDB를 이용한 임시정보 관리
인스턴스에서 발생하는 세션정보나 애플리케이션의 임시정보를 모두 인스턴스에서 관리하는 것이 아니라 Elastic Cache의 Redis나 DynamoDB로 이동하는 것

DynamoDB나 Redis는 모두 key 기반이기 때문에 세션 관리에 최적화
각각의 웹 인스턴스가 본인들의 세션 데이터를 직접 가지고 있는 것이 아니라 DynamoDB나 ElasticCache로 이전
DB에서 자주 액세스되는 데이터는 Elastic Cache에 캐싱하면 웹 인스턴스는 인메모리 기반의 캐시로부터 데이터를 가져오므로 DB 부하를 경량화 시키고 웹 인스턴스는 데이터를 더 빨리 가져올 수 있다.
동적 컨텐츠에 대하여 Amazon CloudFront 이용

동적 컨텐츠도 CloudFront로 이전할 수 있다. CDN으로 동적 컨텐츠를 처리해도 응답시간과 서버 부하를 줄일 수 있다.
6. 사용자 50만명 이상 - 오토스케일링
오토스케일링
인스턴스에 대한 경량화와 아키텍팅이 끝난 후에 오토스케일링을 하는 것이 권장된다. 컴퓨트 클러스터 크기의 최소값과 최대값을 설정해놓고 CloudWatch 메트릭을 통한 스케일 아웃/스케일 인이 가능하다. EC2 구매방식 중 스팟 인스턴스와 온디맨드 인스턴스도 조합해서 사용할 수있다. Autoscaling Group에는 온디맨드와 스팟 유형 모두를 걸어둘 수 있는데, 구매에 성공한 스팟 인스턴스에 대해서 오토스케일링을 걸어놓고, 구매에 실패한 인스턴스는 온디맨드로 보완하는 방식으로 전략을 세울 수 있다.

이 정도 규모가 되었으면 모든 작업들에 대해서 자동화와 모니터링, 로그 분석, 이슈에 대한 즉각적인 대응방안이 필요함. 고객의 피드백도 지속적으로 수용해야 하며 각 서비스가 최대한의 성능을 발휘할 수 있도록 해야 함.
7. 사용자 100만명 이상 - 앞서 언급된 모든 요소를 고려

앞서 언급된 모든 요소를 점검
Multi-AZ
계층간 로드밸런싱
오토 스케일링
느슨한 결합과 서비스 재활용
효율적인 컨텐츠 제공
DB 캐싱과 읽기작업 부하 오프 로드를 위한 읽기 전용 복제본 설정
오토 스케일하는 계층의 세션 상태 이전
8. 사용자가 500만~1000만수준 - 페더레이션, 샤딩
이정도로 유저가 많아지면 아무리 경량화를 하더라도 DB 쓰기작업에서 병목이 발생함
페더레이션(Federation)
데이터베이스를 기능 및 목적에 따라 분리
데이터베이스간 교차-함수 쿼리가 어려움
거대한 단일 함수 및 테이블에는 도움 안 됨

샤딩(Sharding)
DB를 용도에 따라 세분화 하더라도 DB 테이블 자체가 너무 크거나
교차-함수 쿼리가 어려워 DB 운용에 애를 먹을 것 같다면
페더레이션이 적합하지 않은 경우 수평적 확장인 샤딩을 고려
DB를 키값을 통해 저장된 내용을 나눈다
키값을 사용자로 하면 사용자별로 다른 샤드에 저장되도록 나눌 수도 있고, 키값을 날짜로 하면 날짜별로 다른 샤드에 저장되도록 할 수 있다
하지만 샤딩도 마찬가지로 특정 유저가 배치 작업을 돌린다거나, 특정 날짜로 키를 잡았는데 그 날짜에 배치작업이 있는 등 쓰기 작업이 몰리게 되면 이러한 수평적 확장이 효과를 발휘하지 못한다
애플리케이션의 복잡도가 심해질 수도 있기 때문에 샤드를 관리하기 위한 전문 인력이 필요할 수 있다.
특정 일부 기능을 다른 유형의 DB로 변경
NoSQL 도입 검토
관리형 NoSQL 서비스인 DynamoDB 이용
관계형으로 정의할 수 있는 데이터가 아닌, 정제되지 않은 데이터를 저장해야 한다면 적합
ex)
리더보드/득점표
클릭스트림 및 로그 데이터의 빠른 인 업
임시 데이터(장바구니)
핫 테이블
메타 데이터 / 검색 테이블
9. 체크포인트
- Multi-AZ 구성
- 자가 치유가 가능한 서비스를 사용하기를 권장
- 모든 계층 이중화(모든 서비스가 fail될 가능성을 염두에 두고)
- 인프라 내/외부 캐시 적극 활용
- 최대한 인프라 자동화 활용
- 좋은 모니터링/측정/로깅 도구 확보
- 계층을 분해하여 느슨한 결합
- 오토스케일링 적극 사용
- 가급적 직접 만들지 않고 AWS 서비스 활용
- 상황에 맞게 NoSQL 검토
참고자료
천만 사용자를 위한 AWS 클라우드 아키텍처 진화하기 - 이창수 솔루션즈 아키텍트(AWS 코리아)
https://www.youtube.com/watch?v=HI0fPiZpniY
'AWS > AWS 자료 정리' 카테고리의 다른 글
| [AWS Builders 100] AWS와 함께하는 클라우드 컴퓨팅 - 세션 요약 정리 (0) | 2021.01.11 |
|---|---|
| [AWS Builders 100] 클라우드 비용, 어떻게 줄일 수 있을까? - 세션 요약정리 (0) | 2021.01.10 |
| Openswan을 이용한 AWS site to site VPN 구현 (0) | 2021.01.07 |
| AWS 핵심 네트워크 서비스/VPC 정리 (0) | 2020.12.31 |
| [AWS Builders 200] Amazon VPC와 ELB/Direct Connect/VPN 요약 (0) | 2020.12.28 |



